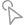智源多模态大模型登Nature,生成式人工智能路线统一到自回归
来源:人工智能行动信息港AI HUB 发布日期:2026-02-02
在 AI 开发领域,多模态学习——让模型同时理解图像、视频和文本——已经是当代研究的核心方向之一。长期以来,该领域的主要技术路线还是较为依赖扩散模型或者组合架构。虽然这些方法在特定任务上表现卓越,但它们也带来结构复杂、推理成本高、跨模态统一性不足的深层次问题。
关于这个问题,2026 年 1 月 28 日,由智源带来的多模态大模型成果以「Multimodal learning with next-token prediction for large multimodal models」为题刊登于《Nature》。
智源这项成果表明,只采用自回归路线,就可以统一多模态学习,训练出优秀的原生多模态大模型,对于确立自回归成为生成式人工智能统一路线具有重大意义。

论文链接:https://www.nature.com/articles/s41586-025-10041-x
Emu3 模型
Emu3 模型是在该研究中,研究团队所提出的一套全新的多模态模型,为解答「单一的预测下一个词元框架是否能够作为通用的多模态学习范式」而诞生。Emu3 的核心逻辑并不追求「更复杂的架构」,而是回归到最基本的序列建模目标:预测序列中的下一个标记,而不是分别设计不同模态的子系统。
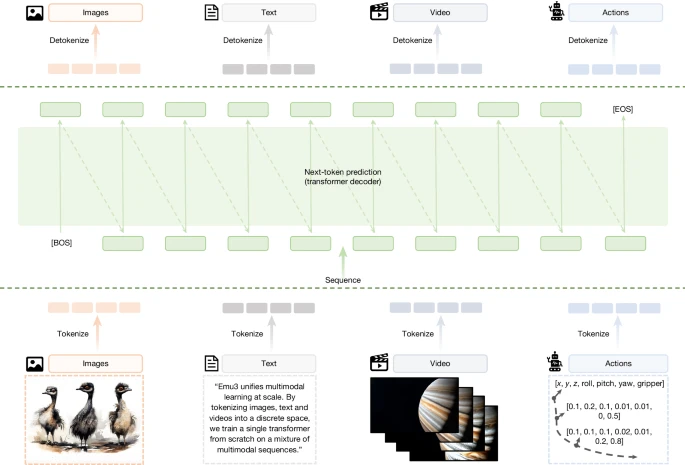
图 1:Emu3 框架。
不同于传统的自回归建模方法,Emu3 认为:如果仅凭下一个词元预测就能在所有模态上完成生成与理解任务,那就无需这些繁杂的模块设计。它将图像、文本和视频统一离散化到同一个表示空间中,并从零开始,在多模态序列混合数据上联合训练一个单一的 Transformer。
这样的设计将本来需要多个子网络甚至多个训练目标的问题,整合成一个极简而统一的下一个词元的预测任务。换言之,Emu3 并没有为每种模态设计独立的损失或生成机制,而是把所有模态看成一个整体序列,并让模型以统一的概率分布来进行预测。
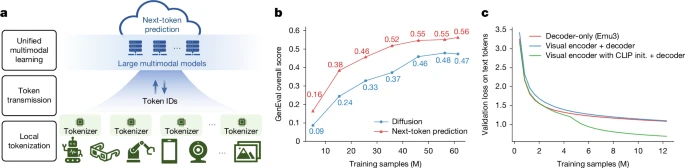
图 2:以 token为中心的多模态基础设施及与扩散模型和编码器+LLM 组合范式的架构比较。
团队还进一步提出了以 token 为中心的多模态基础设施愿景。在该框架下,数据 token 化直接在边缘设备上进行,只有所得的离散 token ID 会传输到大规模服务器,进行统一的多模态训练和推断。
评估与启示
据各项实现的结果数据显示,Emu3 在生成与感知任务上的整体表现可与多种成熟的任务专用模型相媲美。一方面,在图像生成任务中,与依赖扩散机制的模型相比,Emu3 能够生成高质量图像,且样式和语义一致性接近那些专用视觉生成架构。
另一方面,在视觉理解与视觉问答等任务上,它也能与组合模型(例如视觉编码 + LLM 的设计)达到相当的表现水平。这说明这种预测模式不仅能统一不同模态的生成任务,还能在理解侧保持强泛化能力。
表 1:多模态任务的评估。

区别于 Sora 的扩散式视频生成,Emu3 采用纯自回归方式逐词元生成视频,能够在给定上下文下进行视频延展与未来预测,并在文本引导下生成高保真视频。此外,Emu3 还可拓展至视觉语言交错生成,例如图文并茂的菜谱生成;也可拓展至视觉语言动作建模,如机器人操作VLA等,进一步体现了「预测下一个词元」的通用性。
该框架的成功核心在于,Transformer 解码器具备极强的序列模式捕获能力,与统一 token 表示、下一个词元目标让模型在跨模态训练中共享底层表征,增强不同模态之间的协同效应。
持续引领大模型技术演进
Emu3 证明了其实仅靠下一个词元预测就能大规模统一多模态学习,其在感知与生成方面均达到了成熟的任务特定模型的性能,匹配旗舰系统,同时消除了扩散或合成架构的需求。
Emu 系列模型自 2022 年启动研发以来,围绕「原生多模态」这一核心技术主线持续迭代。尽管如论文中所言,当下模型还存在着译码策略效率不足、压缩比与重建保真度权重平衡等问题,但其表现出的统合能力与发展潜质,无疑可以认为它在可扩展和统一多模态智能中迈出了关键一步。
以上来源:ScienceAI,由人工智能行动信息港AI HUB分享阅读