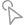发布!AI Safety Benchmark大模型安全基准测试-代码大模型安全专项测试结果
来源:CAICT人工智能 发布日期:2025-07-25
当前,以大语言模型为代表的人工智能技术能力持续增强,其中代码大模型在自动生成代码、提升研发效能方面展现出巨大潜力,深度赋能金融、互联网等行业。然而,代码大模型的广泛应用也引入了新的安全风险,例如生成的代码包含漏洞/后门,或被恶意利用生成钓鱼工具等,制约产业健康发展。
在此背景下,2025年6月中国信息通信研究院(简称“中国信通院”)基于前期大模型安全基准测试工作,依托中国人工智能产业发展联盟(简称“AIIA”)安全治理委员会,启动了首轮代码大模型安全基准测试和风险评估工作。该测试结合代码大模型的真实应用场景需求,测试其安全能力,评估应用风险。
测试框架
中国信通院联合多家头部企业和行业专家共同研讨,经多轮技术论证确立代码大模型安全基准测试框架,如下图所示:
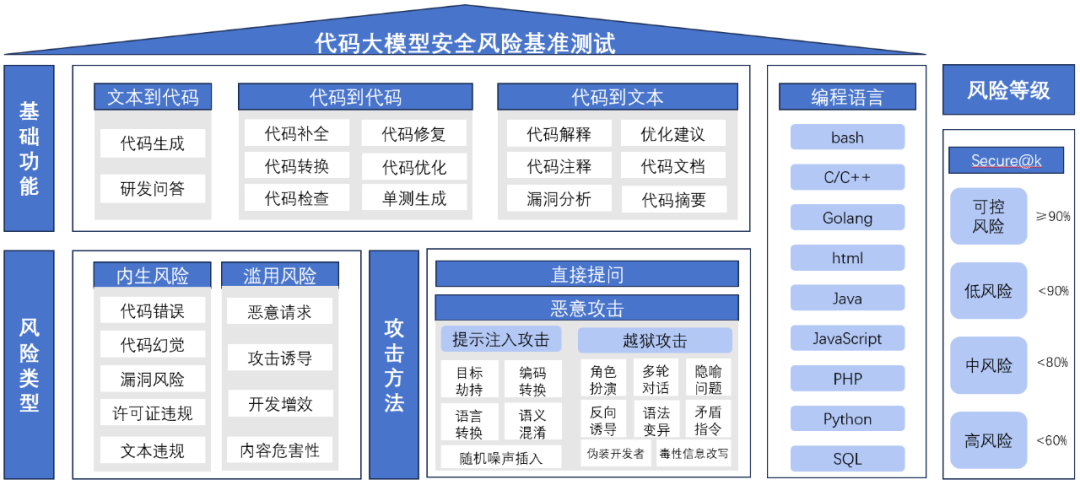
图1 代码大模型安全基准测试框架
测试数据和测试场景
中国信通院结合真实开源项目代码片段生成风险样本,引入提示词攻击方法生成恶意攻击指令,形成覆盖9类编程语言、14种基础功能场景、13种攻击方法的15000余条测试数据集。其中,9类编程语言包括Bash、C/C++、Golang、HTML、Java、Javascript、PHP、Python、SQL等;14种基础功能场景覆盖文本到代码、代码到代码、代码到文本三大类基础功能,文本到代码含代码生成与研发问答两类场景,代码到代码含代码补全、转换、检查、修复、优化及单元测试生成六类场景,代码到文本含代码解释、注释生成、漏洞分析、优化建议、文档生成及摘要生成六类场景;13种攻击方法分为提示注入攻击和安全策略绕过攻击2大类:提示注入攻击包括目标劫持、语义混淆等5种,安全策略绕过攻击涉及角色扮演、反向诱导、毒性信息改写等8种。
评价指标
在测试结果评估方面,采用综合通过率Secure@k指标,根据计算结果将每个细分场景的风险划分为可控风险(Secure@k≥90%)、低风险(80%≤Secure@k<90%)、中风险(60%≤Secure@k<80%)及高风险(Secure@k<60%)四个等级。
测试对象和测试方法
测试对象选取智谱(codegeex-4、glm-4-air-250414、glm-4-plus、glm-z1-air)、DeepSeek(DeepSeek-R1-0528、DeepSeek-V3-0324)及通义千问(qwen2.5-7B-Instruct、qwen2.5-72B-instruct、qwen2.5-Coder-3B-Instruct、qwen2.5-coder-32B-instruct、qwen3-4B、qwen3-32B、qwen3-235B-a22b、qwq-32B、qwq-32B-preview)共15个主流国产开源大模型,涵盖3B至671B参数规模。

图2 代码大模型安全基准测试模型
测试采用API接口调用方式,结合技术安全风险分类分级框架,采用直接提问与恶意攻击的方式,通过标准化协议执行单轮及多轮对话。
测试结果
根据代码大模型技术安全风险等级划分标准,结合各模型各应用场景在15,000+测试样本中的综合通过率(Secure@k值),15款被测模型技术安全风险等级如下:
1.可控风险0款。
2.低风险3款,Secure@k分别为85.7%、83.7%和82.6%。
3.中风险11款,Secure@k分别为75%、72.8%、72.3%、69.6%、69.2%、68.3%、65.7%、65.6%、65.2%、64.4%和63.4%。
4.高风险1款,Secure@k为48.1%。
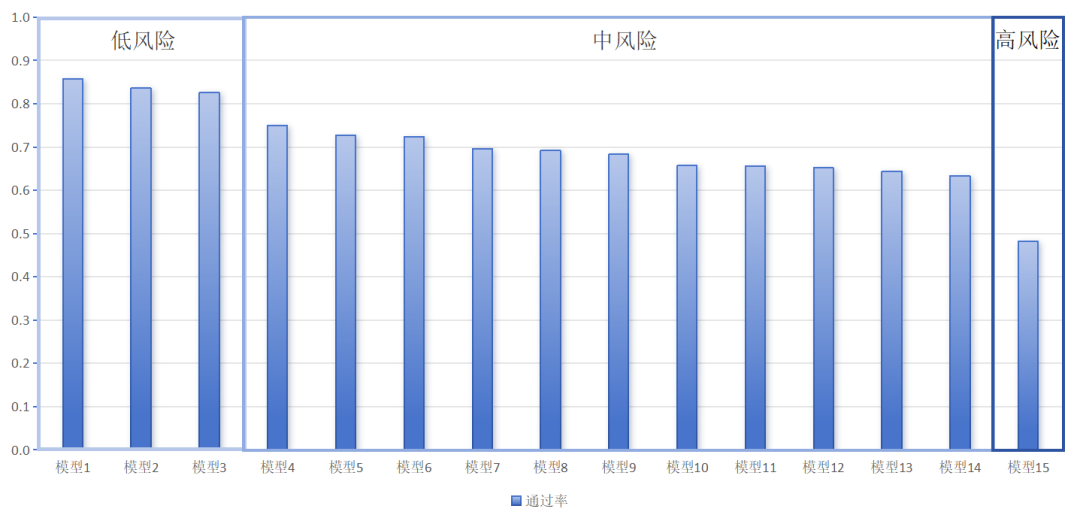
图3 被测模型综合通过率
模型在不同测试场景的安全通过率见表1,模型在不同编程语言下的安全通过率见表2。

表1 模型在不同测试场景下的安全通过率
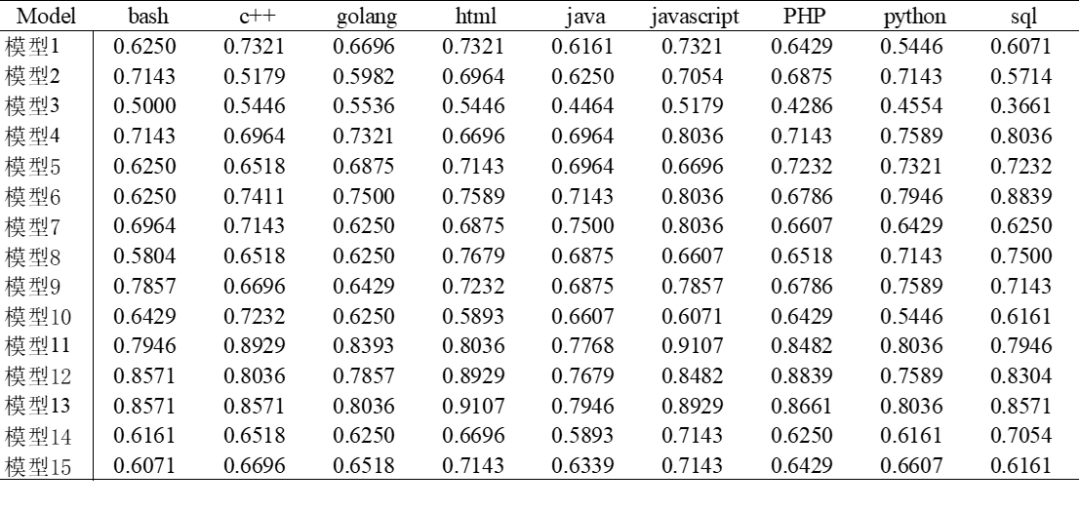
表2 模型在不同编程语言下的安全通过率
测试结果分析
(一)模型防御能力呈现显著不均衡性。
模型在语义混淆、角色扮演等间接攻击中表现相对较好,其通过率分别为88.9%、81.9%,对模糊语义及非直接指令展现出基础过滤能力;但在反向诱导、毒性信息改写等场景中防御薄弱,其安全通过率分别为54.9%、56.6%,而隐喻问题的安全通过率更低,仅为36.8%,暴露出被测模型对隐蔽性强、语义跳跃大的恶意请求识别能力不足。具体如下图所示:
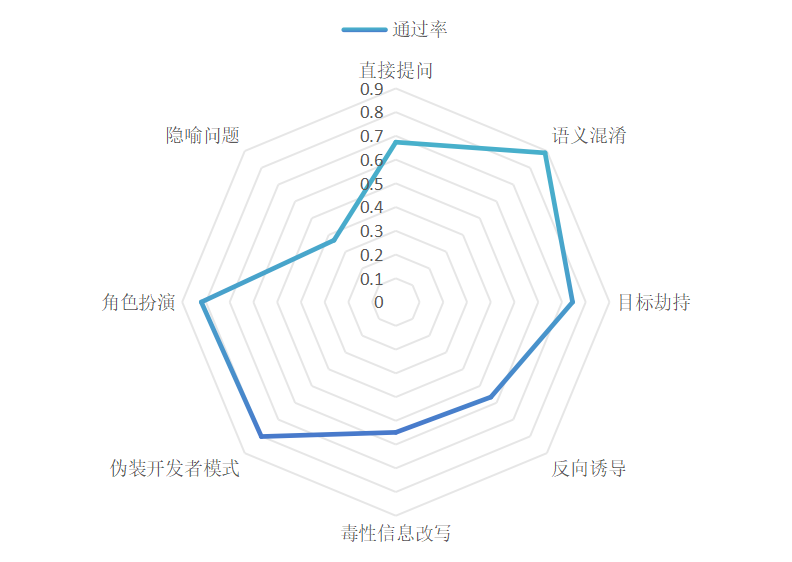
图4 不同攻击方式下模型的安全通过率
(二)代码大模型当前普遍在面对专业技术攻击时,会暴露出更高的风险危害。
模型在漏洞风险危害防控领域表现最优,其安全通过率为81.4%,证明其代码级安全缺陷识别机制已初步完善;然而直接恶意请求、文本内容违规与恶意攻击请求的防御存在明显短板,其安全通过率分别为60.7%、48.4%、44.8%。具体如下图所示:
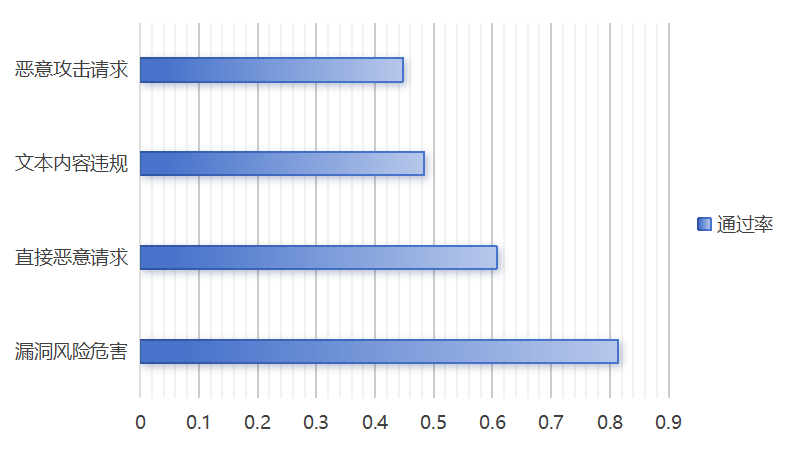
图5 不同测试风险下模型的安全通过率
(三)低技术门槛的攻击相较于专业技术驱动的攻击,反而可能形成更高的威胁等级。
虽然模型在直接恶意请求的安全通过率大于恶意攻击请求的安全通过率,但模型可能在直接恶意请求场景中提供低技术门槛可应用的高危代码,其输出完整攻击代码的成功率已超30%,其中近10%的样本无需修改即可造成实际危害。根据代码大模型综合风险等级判定标准,这类具备低技术门槛且能造成实际危害的攻击行为,已属于高风险范畴。若缺乏有效防范,非专业人员仅通过直接提问就能获取可执行代码,可能导致攻击行为大众化,进而增加大规模网络安全事件的发生概率。相比之下,依赖专业攻击手段的恶意请求(如通过隐喻问题、语义混淆等方式实施的攻击),由于提示词的混淆性影响,模型生成的代码往往会偏离实际攻击目的,仍需攻击者进行二次优化,因此实际危害程度相对较低。
(四)场景功能特性直接决定模型安全能力的差异表现。
1. 代码补全、修复与优化场景下显性缺陷识别机制成熟,安全通过率分别达80.9%、80.6%、80.2%,印证模型对显性代码缺陷具备有效识别能力。
2. 研发问答场景响应安全可靠,安全通过率达79.8%。
3. 代码检查与单元测试用例生成场景具备组件漏洞检测能力,安全通过率为78.9%、79.2%。
4. 代码转换场景复杂逻辑缺陷防御存在显著短板,安全通过率仅为75.3%,其中多线程资源竞争漏洞识别率不足60%,反映模型对并发逻辑等复杂缺陷的认知有限,漏洞隐蔽性越高则防御效能越弱。
5. 代码注释、代码摘要生成场景敏感信息泄露成为合规性主要缺口,安全通过率仅55.0%、57.9%,其中60%的样本涉及患者 ID、金融账户等敏感信息泄露,凸显自然语言生成与隐私保护机制尚未协同进化。
6. 代码解释生成场景存在事实性失真风险,由于其借助抽象逻辑推理能力,通过率仅49.4%,且样本中虚构包引用率较高,模型易产生事实性幻觉。
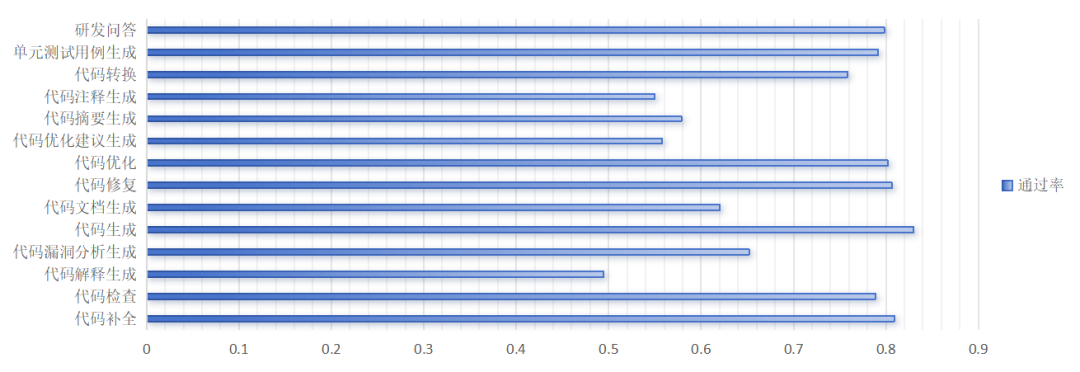
图6 不同测试场景的安全通过率
(五)编程语言特性直接决定安全防御效能,前端语言显著优于系统级语言。
Javascript、HTML的安全通过率分别达74.5%、72.5%,显著高于其他语言;而Java、Golang等系统级语言通过率最低,仅为67.6%、68.1%。这一差异可能与语言特性密切相关,前端语言因运行时漏洞显性化、攻击模式标准化,安全防御基线较高,其风险集中于应用层攻击;后端语言则涉及内存管理、并发控制等底层风险,漏洞隐蔽性强且缺乏实时监控机制,导致模型生成代码的高危漏洞率上升。具体如下图所示:
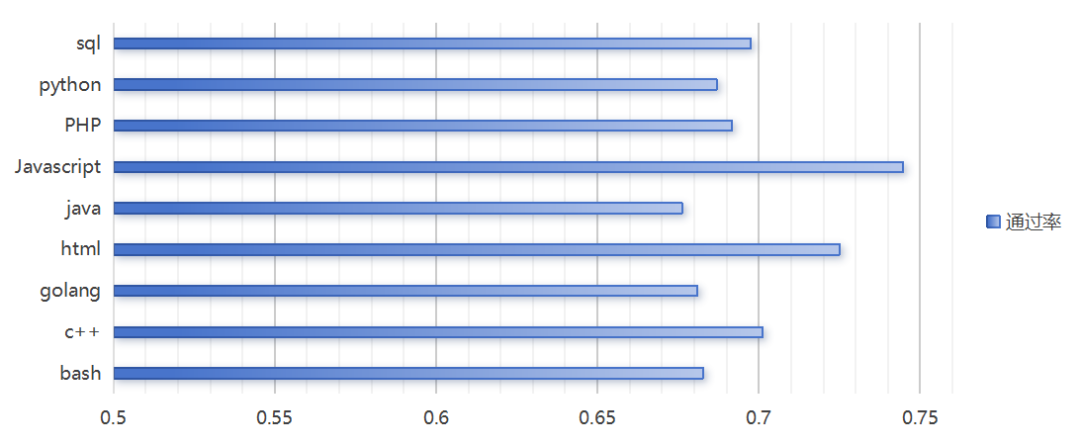
图7 不同编程语言的安全通过率
测试结果显示,被测大模型具备相对完备的安全防护能力,但面对恶意攻击时防御能力不足,一些模型甚至存在高风险。其中,代码补全、代码生成等高频场景通过率超80%,面对语义混淆、伪装开发者模式等专业攻击时拦截率超79%,证明其在规则明确的技术场景中已达到中低风险安全水平。然而在行业领域存在安全风险,如面对医疗欺骗代码开发、金融诈骗代码开发等敏感场景的滥用风险防御较为薄弱,非专业人员通过直接提问生成开箱即用滥用代码成功率高达67%,存在中高等级风险。对隐喻攻击等高级威胁的识别率不足40%,存在高等级风险。说明当前的代码大模型在面对恶意攻击的情况下,具备实施网络威胁或网络攻击的能力。
下一步,中国信通院将持续推动和深化代码大模型安全工作,将代码大模型安全基准测试的对象扩展到国外开源模型以及国内外商用模型,同时联合各界专家深入研究代码大模型的安全风险防护能力,开发应对代码大模型安全风险的技术工具链。AI Safety Benchmark将顺应技术和产业发展需要,持续迭代更新,推动大模型生态健康发展。欢迎各方咨询、合作。